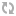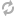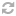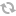robots.txt文件
robots.txt只能存放于网站的根目录下,置于除此之外的任何地方均不会被Spider发现。
每个网站,或每个域名(包括子域名),只能有一个robots.txt。
文件名“robots.txt”为小写字母,其他如Robots.txt或robots.Txt是不正确的,命名错误将会被Spider忽略。
正如上篇文章中介绍的,Spider在网站内找不到robots.txt时将会被重定向到404 错误页面,这便有可能阻碍Spider抓取和收录页面。虽然这并不一定会发生,但很多时候我们没必要冒这样的风险,一般来说,即使我们对网站的所有内容都没有限制,对所有的搜索引擎Spider 都欢迎,最好也在根目录下创建一个robots.txt文件:
User-agent: *
Disallow:
robots.txt的语法规则
在Disallow项中使用小写字母,即文件名和目录名使用小写字母,特别在对大小写敏感的Unix下更要注意。
robots.txt惟一支持的通配符是在User-agent使用的“*”,其代表所有的Spider。除此之外,别的通配符均不可用。这方面的错误常见于在文件名或目录名中使用通配符。
robots.txt的限定项
在User-agent和Disallow项的设定中,每行只允许有一个设定值,同时,注意不要有空行。至于行数,则没有限制,理论上说可以根据需要创建具有无数行的robots.txt。
下面即是一个错误的例子
User-agent: *
Disallow: /dir1/ /dir2/ /dir3/
正确设置应为:
User-agent: *
Disallow: /dir1/
Disallow: /dir2/
Disallow: /dir3/
robots.txt中的文件与目录
既定某个文件拒绝索引时,格式为文件名(包括扩展名),其后无“/”,而限定目录时,则需在目录名后加“/”。如下面的示例:
User-agent: *
Disallow: /file.html
Disallow: /dir/
特别注意的是,不要省略掉目录名后的“/”,不然,Spider便极有可能误读相应的设置。
robots.txt中限定项的顺序
请看下方的示例:
User-agent: *
Disallow: /
User-agent: Googlebot
Disallow:
该设定本意是想允许Google访问所有页面,同时禁止其他Spider的访问。但在这样的设置下,Googlebot在读取前2行后便会离开网站,后面对其的“解禁”完全失去了意义。正确的格式应为:
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /
robots.txt中的注释
尽管在robots.txt的标准中,可以在限定项的后面使用“#”添加注释,如下面的例子
User-agent: Googlebot #这是对Google的设置
Disallow:
但很多研究与测试表明,不少Spider对这样格式的解读存在问题。为确保其能更好地工作,最好采用如下设置:
#这是对Google的设置
User-agent: Googlebot
Disallow: